Link : https://arxiv.org/pdf/2106.09685
Why
- For down-stream applications, full parameter fine-tuning that fine-tunes all the parameters, are most resource-intensive and time consuming.
- Mitigated by adapting only some parameters or learning external modules for new tasks, not good as it introduce inference latency, or reduce the models’ usable.
- Usually often fail to match the fine-tune baselines, posing a trade-off between efficiency and model quality.
- Need a new way !
Code
from perf import LoraConfig, get_peft_model
lora_config = LoraConfig(
task_type = TaskTyle.SEQ_2_SEQ_LM # Type of task
r = 8 # Rank of the low-rank matrices
lora_alpha = 16 # Alpha parameter for scaling
lora_dropout = 0.1 # Dropout rate
bias = 'none' # Options: 'none', 'all', 'lora_only'
target_modules = ["q", "v"] # Specify target modules in the model
)- task_type
- Description: Specifies the type of task for which the model is being fine-tuned.
- Values:
TaskType.SEQ_2_SEQ_LMfor sequence-to-sequence language modeling.TaskType.CAUSAL_LMfor causal language modeling.TaskType.TOKEN_CLASSIFICATIONfor token classification.TaskType.SEQUENCE_CLASSIFICATIONfor sequence classification.
- Usage: This helps tailor the fine-tuning process to the specific requirements of different NLP tasks.
- r
- Description: The rank of the low-rank matrices used to approximate the weight updates.
- Values: Positive integer (e.g.,
4,8,16). - Usage: A lower rank reduces the number of trainable parameters, making the fine-tuning process more efficient. However, too low a rank might underfit the data.
- lora_alpha
- Description: A scaling factor applied to the low-rank updates.
- Values: Positive integer (e.g.,
16,32,64). - Usage: This parameter scales the updates from the low-rank matrices. Higher values can increase the influence of the low-rank updates.
- lora_dropout
- Description: Dropout rate applied to the low-rank matrices during training.
- Values: Float between
0and1(e.g.,0.1,0.05). - Usage: Dropout helps to prevent overfitting by randomly setting some weights to zero during training. A dropout rate of
0.1means 10% of the weights will be set to zero.
- bias
- Description: Specifies which biases to apply LoRA to.
- Values:
"none": No biases are updated."all": All biases are updated."lora_only": Only the biases in the low-rank matrices are updated.
- Usage: This controls whether and how the biases in the model are fine-tuned alongside the main weight updates.
- target_modules
- Description: Specifies which modules (layers) in the model to target for applying LoRA.
- Values: List of strings representing module names (e.g.,
["q", "v"]). - Usage: This allows fine-tuning specific parts of the model, such as query (
q) and value (v) projection layers in transformers. By targeting specific modules, you can focus the fine-tuning effort where it’s most needed.
Insight
- Learned over-parametrized models in fact reside on a low intrinsic dimension.
- Low-Rank Adaptation is based on that the change in weights during model adaptation also has a low ‘intrinsic rank’.
- LoRA allows us to train some dense layers in neural network indirectly optimizing rank decomposition matrices of the dense layers’ change during adaptation, while keep the pre-trained weights frozen.
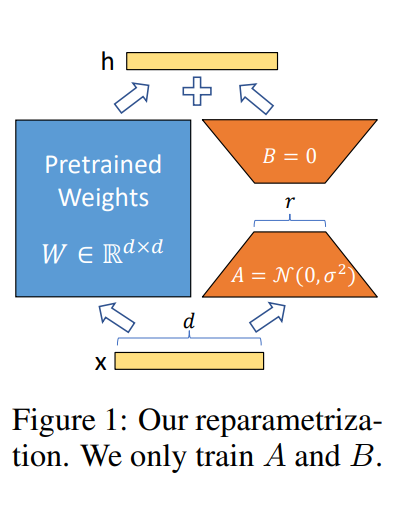
LoRA advantages
- many small LoRA modules can be build for different tasks on a shared pre-trained model. By freezing the model and efficiently switch tasks by replacing the matrices A and B as in fig 1.
- LoRA makes training more efficient and lowers the hardware barrier to entry by 3 times.
- Linear design allows us to merge the trainable matrices with the frozen weights when deployed, introducing no inference latency
- LoRA is orthogonal to other methods and can be combined with many of them.
Other Methods disadvantages
- Adapter Layers Introduce Inference Latency
- Directly Optimizing the Prompt is Hard
Math
During full fine-tuning, the model is initialized to pre-trained with and updated to by repeatedly following the gradient to maximize the conditional language modeling objective :
where = pre-trained autoregressive language model and where is training dataset of context-target pairs.
LoRA is more parameter-efficient approach, where the is further encoded by a much smaller-sized set of parameters with . The task of finding thus becomes optimizing over :
Thus the number of trainable parameters can be as small as 0.01% of .
Method
A neural network contains many dense layers which perform matrix multiplication. The weight matrices in these layers typically have full-rank. When adapting to a specific task, previous research shows that the pre-training language model have a low ‘instrisic dimension’ and can still learn efficiently despite a random projection to a smaller subspace. Inspired by that, author hypothesize the updates to the weights also have a low ‘instrisic dimension’ during adaptation