Link : https://arxiv.org/pdf/2407.09025
Spreadsheets
- World runs on spreadsheets.
- Spreadsheets are ubiquitous for data management and extensively utilized within platforms like Microsoft Excel and Google Sheets.
LLMs don’t like Spreadsheets
- Spreadsheets pose unique challenges for LLMs due to their expansive grids that usually exceed the token limitations of popular LLMs, as well as their inherent two-dimensional layouts and structures, which are poorly suited to linear and sequential input.
SheetCompressor
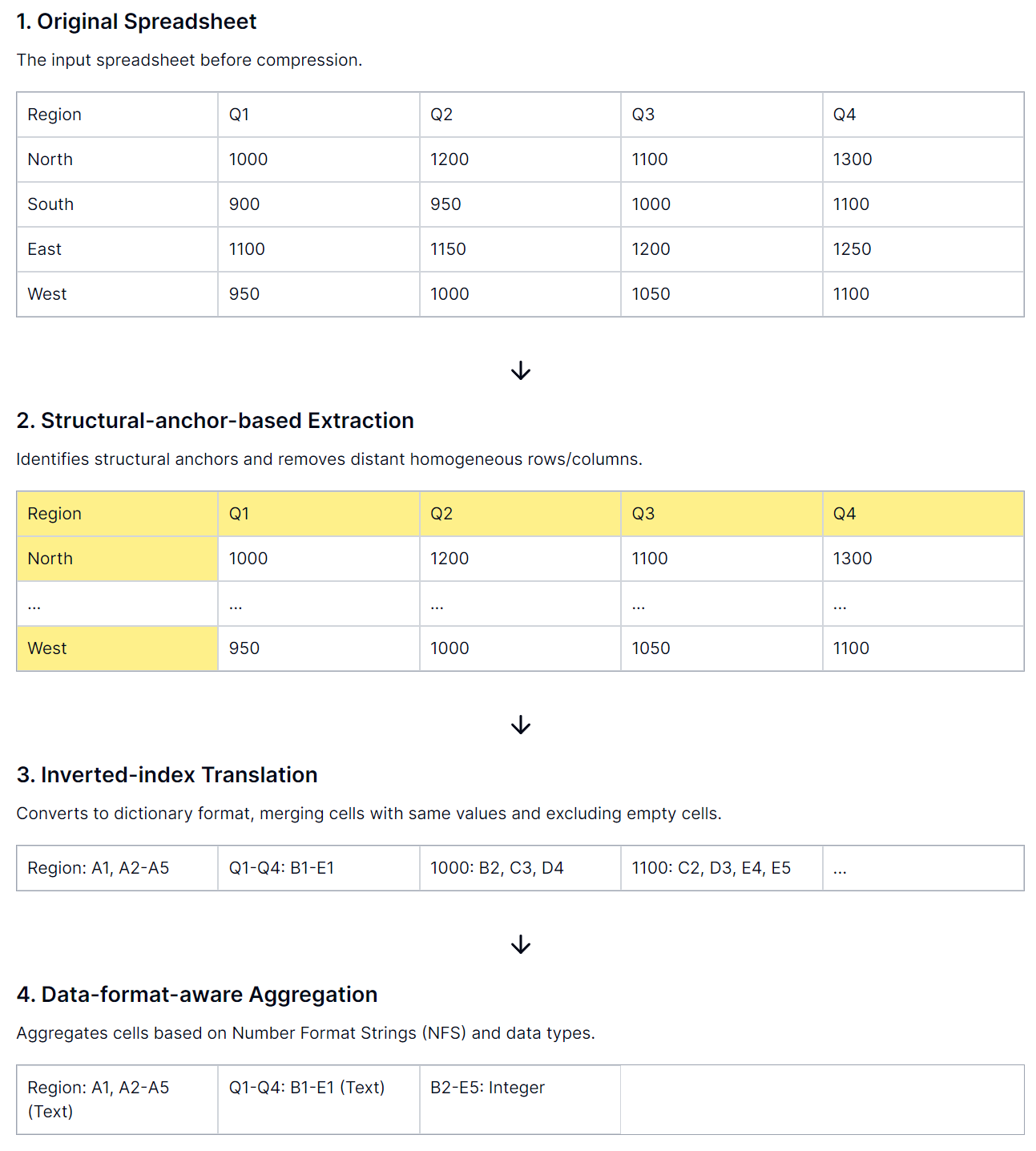
Novel encoding framework comprising three portable modules
-
Structural Anchors for Efficient Layout Understanding: First, identify structural anchors-heterogeneous rows and columns at table boundaries. Second, remove homogeneous rows and columns, producing a condensed “skeleton”.
-
Inverted-Index Translation for Token Efficiency: Author departs from traditional row-by-row and column-by-column serialization and employ a lossless inverted-index translation in JSON format. I.e. create a dictionary that indexes non-empty cell texts and merges addresses with identical text, optimizing token usage while preserving data integrity.
-
Data Format Aggregation for Numerical Cells: Recognizing that exact numerical values are less crucial for grasping spreadsheet structure, we extract number format strings and data type from these cells. These adjacent cells with same formats/types are clustered together.
SHEETCOMPRESSOR is good at reducing token usage for spreadsheet encoding by 96%.
Example
Contribution of paper
- Propose SpreadsheetLLM, first work that leverage LLMs for understanding and analyzing spreadsheet data.
- SheetCompressor, an innovative encoding framework to compress spreadsheets for LLMs with efficient encoding.
- Fine-tune a variety of cutting-edge LLMs to achieve optimal performance on sheet table detection.
- For downstream tasks, author propose Chain of Spreadsheet (CoS).
Results
- Enhanced Performance with various LLMs: Fine-tuned GPT4 model achieved the F1 score of approximately 76% across all datasets.
- Benefits for Large Spreadsheets: Compression method significantly boosted performance on large spreadsheet, where the challenges were most pronounced due to model token limits.
- Improvement in In-Context Learning.
- Significant Cost Reduction.
tldr.
- Novel framework to processing and understanding of spreadsheet data by leveraging the capabilities of LLMs.
- Novel encoding method, that addresses the challenges posed by the size, diversity, and complexity inherent in spreadsheets.
- Encoding method, achieves substantial reduction in token usage and computational cost.