Link : https://arxiv.org/pdf/2406.18665v
Demo : https://routerllm.streamlit.app/
Notes
- Not all LLMs are created equal.
- Broadly speaking, large models tend to be more capable but come at a higher cost, while smaller models tend to be less capable but cheaper to serve. The heterogeneous landscape presents a dilemma in the practical deployment of LLMs in real-world applications.
- LLM routing is a promising solution to this problem.
Router is tough
- how to optimize for quality of model responses with minimizing cost.
- router need to infer the intent, complexity, and domain of incoming query
- also need to understand candidate models’ capabilities
- router model needs to be economical, fast, and adaptive to the evolving model landscape.
Problem
More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective.
- different LLM models
- Each model as abstraction of a function mapping query to answer
- Router is is an -way classifier
The challenge of routing involves achieving an optimal equilibrium between increasing response quality and reducing cost.
For preference data:
- where is a query,
- is a label representing the comparison outcome of comparing ‘s quality on ,
Solution
Principled framework for learning a binary routing function.
Between and from preference data
is defined using 2 components.
-
Win Predication Model: probability of winning for i.e.
By learning the winning probability on preference data, the author capture the strengths and weaknesses of both models on various kinds of queries.
-
Cost Threshold: which converts winning probability into routing decision and .
controls the quality/cost trade-off : a higher threshold imposes a stricter cost constraint.
Final response is denoted as router’s response i.e. , which represents the response generated by either the weak or strong model, depending on the router’s decision.
Preference Data
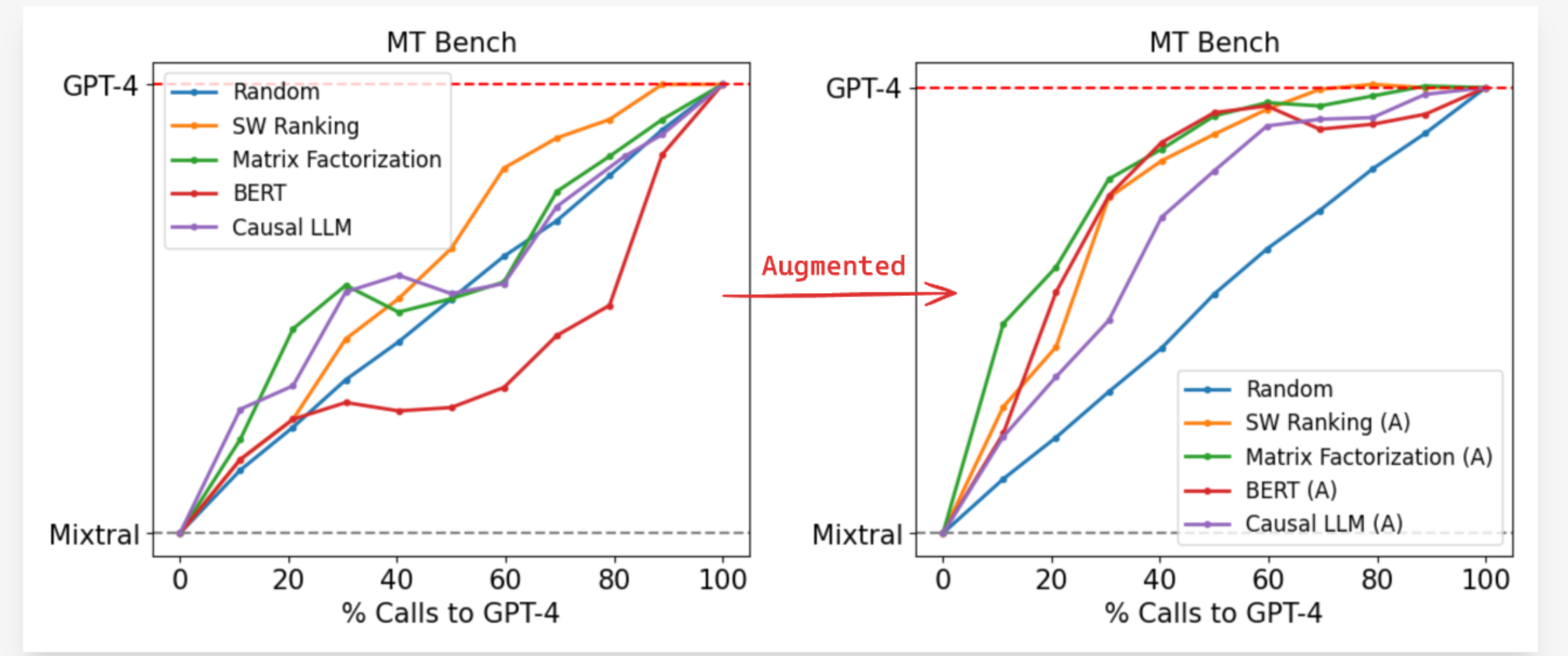
80k battles from the Chatbot Arena platform with some Data Augmentation. See paper for more information.
Routing Approaches
(i’m not very clear on this)
Method for learning the win predication model from preference data.
Similarity-weighted (SW) ranking: Bradley-Terry model is adopted by author here. Given a user query , compute a weight for each query in the train set based on its similarity to .
- denotes a query embedding.
Matrix factorization: As in recommendation systems, it used to capture the low-rank structure of user-item interactions.
BERT classifier: A standard text classification method on based on BERT-base architecture.
Casual LLM classifier: Instruction-following paradigm, i.e. input as instruction prompt containing the user query, and output the win probability in a next-token prediction fashion instead of using a separate classification head.
tldr.
For both the matrix factorization router and the similarity-weighted ranking router, author used text-embedding-3-small to embed the input query.
Author perform full parameter finetuning on both BERT and Causal LLM.
Contribution of paper
- Formulate the LLM routing problem to explore the trade-off between cost and response quality.
- Router training framework based on human preference data and augmentation techniques.
- Open-source code and preference data
Similar works
- LLM-BLENDER employs an ensemble framework that calls multiple LLMs at inference and uses a router model to select the best response.
- Frugal-GPT employs an LLM cascade, sequentially querying LLMs until a reliable response is found.
- Hybrid-LLM similar to this paper in framework but differs in three key ways: it uses synthetic preference labels derived via BARTScore, relies on a single BERT-based router architecture, and limits evaluation to in-domain generalization.
Result