Link : https://arxiv.org/pdf/2407.21783
Index
Notes
- a pre-training stage in which the model is trained at massive scale using straightforward tasks such as next-word prediction or captioning
- 405B on 15.6 T tokens using a context window of 8K tokens
- pre-training stage in followed by a continued pre-training stage increases the window to 128K tokens.
- a post-training stage in which the model is tuned to follow instructions, align with human preferences, and improve specific capabilities.
- align the model with human feedback in several rounds
- supervised finetuning on instruction tuning data
- and Direct Preference Optimization
- also integrate tool-use
- three key levers in the development of high-quality foundation models :
- data : 15T multilingual tokens
- scale :
- managing complexity : focus on maximizing training stability
- stand dense Transformer model architecture
- simple post-training procedure
- supervised finetuning (SFT)
- rejection sampling (RS)
- direct preference optimization (DPO)
Insights
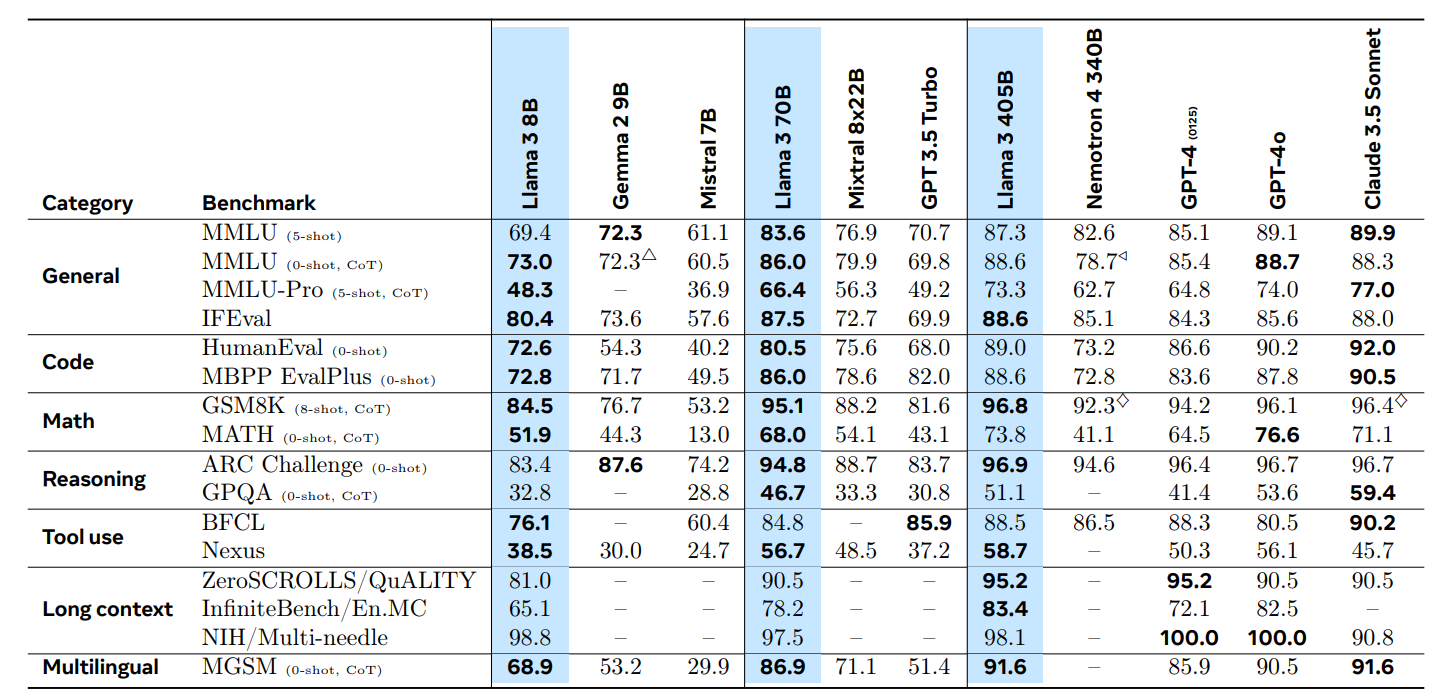
- Scaling laws for foundation models holds.
Pre-Training
Steps
- the curation and filtering of a large-scale training corpus
- the development of a model architecture and corresponding scaling laws to determining model size
- the techniques for efficient pre-training at large scale
- the development of a pre-training recipe
Data
1. Web Data Curation
- PII and safety filtering : remove unsafe content or high volumes of personally identifiable information (PII)
- Text extraction and cleaning : raw HTML → custom parser → useful raw data
- De-duplication : several rounds of de-duplication
- URL-level de-duplication : keep the most recent version of pages
- Document-level de-duplication : perform global MinHash, on entire dataset to remove near duplicate documents
- Line-level de-duplication : aggressive line-level de-duplication similar to
ccNet. Remove lines that appeared more than 6 times.
- Heuristic filtering : remove additional low-quality documents, outliers, and documents with excessive repetitions
- use duplicated n-gram coverage ratio to remove lines that consist of repeated content such as logging or error messages.
- use ‘dirty word’ counting to filter out adult websites.
- use token-distribution Kullback-Leibler divergence to filter out documents containing excessive number of outlier tokens.
- Model-based quality filtering : model-based quality classifiers to sub-select high-quality tokens
- fast classifiers such as
fasttexttrained to recognize if a given text would be referenced by Wikipedia - Roberta-based classifiers trained on Llama 2 predictions
- use DistilRoberta to generate quality scores for each documents for efficiency reasons
- fast classifiers such as
- Code and reasoning data : similar to DeepSeek-AI, build domain-specific pipelines that extract code and math-relevant web pages
- both the code and reasoning classifiers are DistilledRoberta models trained on web data annotated by Llama 2
- prompt tuning to target web pages containing math deduction, reasoning in STEM area and code interleaved with natural language
- as token distribution of code and math is substantially different than natural language, these pipelines implement domain-specific HTML extraction, customized text features and heuristics for filtering.
- Multilingual data : Similar to processing pipeline for English
fasttext-based language identification model to categorize docs into 176 languages- perform doc-level and line-level de-duplication within each language cat
- language-specific heuristics and model-based filters to remove low-quality docs
2. Determining the Data Mix
- Use a classifier (Knowledge classification) to categorize the type of information, followed by scaling law experiments on smaller models with different mix of data types (Scaling laws for data mix).
- Final data mix contains roughly
- 50% of token of general knowledge,
- 25% of mathematical & reasoning tokens,
- 17% code tokens,
- 8% multilingual tokens.
3. Annealing Data (not clear on this)
- For the final 40M tokens, linearly annealed the learning rate to 0, with upsample data sources of very high quality
- Annealing improved performance of smaller model (8b) but on 405b, improvements are negligible.
Model Arch
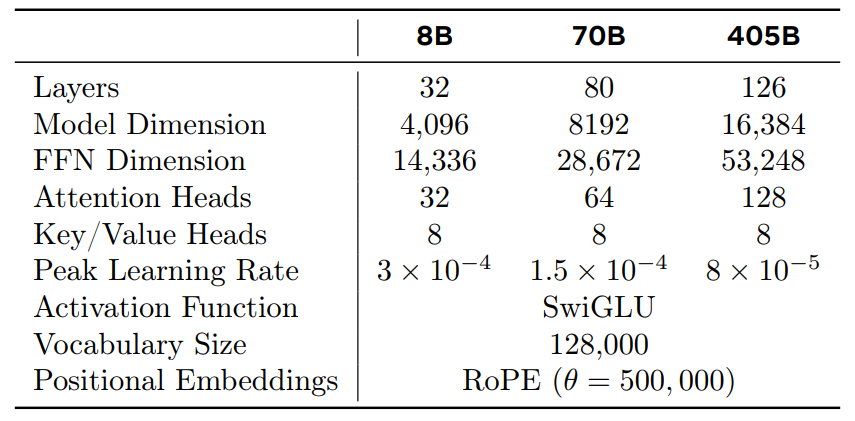
Standard, dense Transformer architecture. Llama 3 does not deviate significantly from Llama and Llama 2.
Few small modifications:
- use grouped query attention with 8 key-value heads to improve inference speed and to reduce the size of key-value caches during decoding
- attention mask that prevents self-attention between different documents within the same sequence. Important in continued pre-training on very long sequences
- vocabulary with 128K tokens. 100K from
tiktokentokenizer with 28K additional tokens. Compare to Llama 2, compression rates are higher from 3.17 to 3.94 - increase the RoPE base frequency hyperparam to 500,000. RoPE uses rotation the complex plane to encode positional information.
1. Scaling Laws
- To find the ideal relation between compute budget and optimal number of training tokens,
- Meta found by experimenting.
- Extrapolation of the resulting law to suggests training a 402B model on 16.55T tokens.
Infrastructure, Scaling, and Efficiency
skipped readin
Compute
- 16K H100 GPUs, running on 700W TDP with 80GB HBM3
Storage
- Used Tectonic, Meta’s general-purpose distributed file system.
- 240PB of storage with 2TB/s sustainable throughput.
- Checkpoint saving each GPU’s model state, was a major challenge as the highly bursty checkpoint writes saturate the storage fabric.
Network
- Really badass, and out of my understanding.
Training Recipe
The pre-training of Llama 3 405B consist of three main stages:
- initial pre-training
- long-context pre-training
- annealing
Initial Pre-Training
- AdamW (Adaptive Moment Estimation with Weight Decay) with peak learning rate of , a linear warm up of 8,000 steps, and cosine learning rate schedule decaying to over 1,200,000 steps.
- Lower batch size early in training, and increase it subsequently.
- at 0M tokens, batch size 4M and sequence length 4096
- at 252M tokens, batch size 8M and sequence length 8192
- at 2.87T tokens, batch size 16M and sequence length 8192
import torch.optim as optim
model = nn.Linear (10,1)
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
Long Context Pre-Training
- Final stages of pre-training, trained on long sequences to support context windows of up to 128K tokens.
- increased context length gradually in six stages, from original 8K context window and ending on 128K context window.
- this was done with approx. 800B training tokens.
Annealing
- Adjusted the final 40M tokens with upsample data sources of very high quality and learning rate of 0.
Post-Training
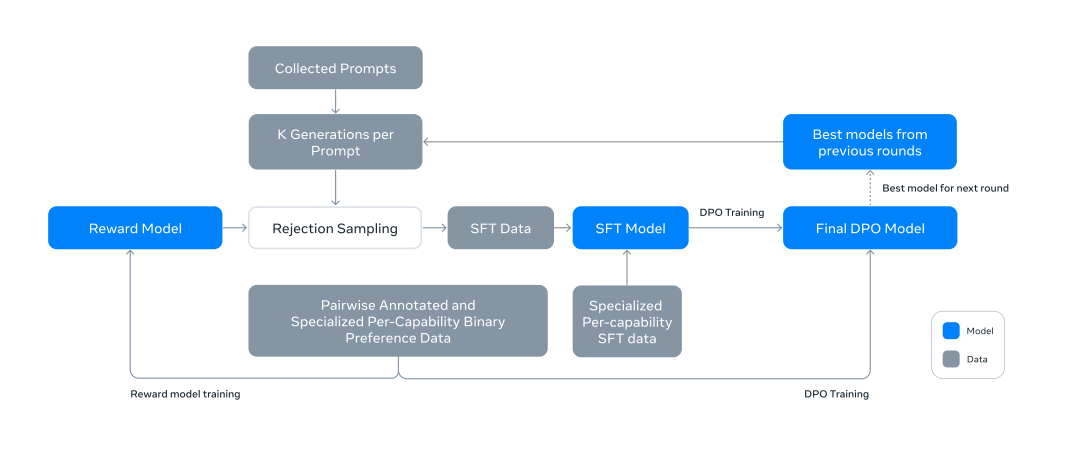
Multiple rounds of aligning the model with human feedback. Each round of post-training involves supervised finetuning (SFT) followed by Direct Preference Optimization (DPO) on examples collected either via human annotations or generated synthetically.
Modeling
1. Chat Dialog Format
- multi-message chat protocol which uses various special header and termination tokens
- header tokens are used to indicate the source and destination of each message in a conversation
- termination tokens indicate when it is the time to alternate between human and AI to speak
2. Reward Modeling
- Similar to Llama 2, using preference data to train reward model (RM) on pre-trained checkpoint.
- With preference ranking of
- edited (1)
- chosen (2)
- rejected (3)
3. Supervised Finetuning
- Using rejection-sampled data and synthetic data (and other data sources), the pre-trained model is fine-tuned using standard cross entropy loss on the target tokens (while masking loss on prompt tokens)
- Learning rate of over the course of to steps.
4. Direct Preference Optimization
- The SFT models are further trained with DPO for human preference alignment.
- The following modifications to DPO are applied.
- Masking out formatting tokens in DPO loss: Reasoning being the presence of common tokens in both chosen and rejected responses leads to a conflicting learning objective as the model needs to increase and reduce the likelihood of these tokens simultaneously.
- Regularization with NLL loss: added additional negative log-likelihood (NLL) with scaling coefficient of 0.2.
- This helps further stabilize DPO training by maintaining desired formatting for generation and preventing the decrease of log probability of chosen responses.
5. Iterative Rounds
- The above methods are applied in 6 rounds.
- In each cycle, author collect new preference annotations and SFT data, sampling synthetic data from the latest models.
Post-training Data
1. Preference Data
- Method
- deploy multiple models for annotation after each round
- sample two responses for each user prompt
- models differ by different data mixes and alignment recipes
- ask annotators to rate their preference on 4 levels
- significantly better
- better
- slightly better
- marginally better
- optional editing step resulting in 3 responses ranked
- edited
- chosen
- rejected
2. SFT Data
- Finetuning data - Prompts from human annotation collection with rejection-sampled responses. - Synthetic data targeting specific capabilities - Small about of human-curated data.
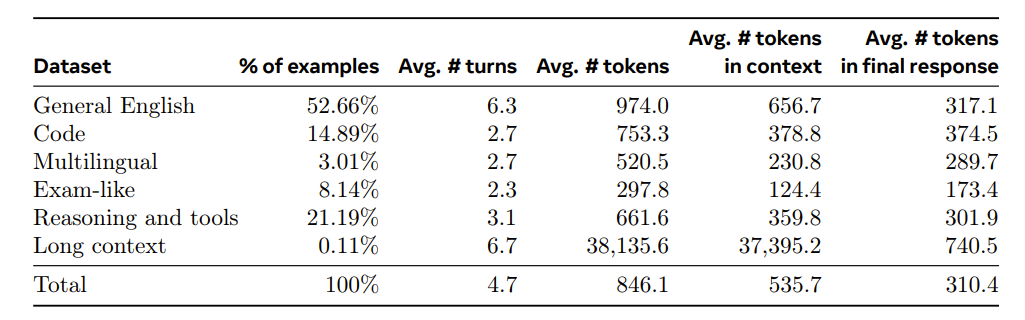
Post Training rounds
with each round, Meta develop a stronger Llama 3 variants that is used to collect larger datasets that cover a wide range of complex capabilities
- Rejection sampling: For each prompt collected during human annotation, sample K outputs from the latest chat model checkpoint and use reward model to select the best candidate, consistent with Bai et al. In later rounds, introduce system prompts to steer RS responses.
3. Data Processing and Quality Control
*most of the training data is model-generated
- Data cleaning: In early rounds, a number of undesirable patterns immerge, such as excessive use of emojis or exclamation points.
- Implemented a series of rule-based data removal and modification strategies to filter/clear problematic data. Example : overly-apologetic tonal issues
- Data pruning: Collection of model-based techniques to remove low-quality training samples.
- Topic classification: finetuned Llama 3 8B as topic classifier, and perform inference over all data to classify into both coarsely-grained buckets and fine-grained buckets.
- Quality scoring: using reward model and Llama-based signals to get quality score for each sample.
- For an RM-based score, consider data from top quartile of RM scores as high quality.
- For a Llama-based score, three-point scale on general English (accuracy, instruction following, and tone/presentation) and a two-point scale for coding data (bug identification and user intention). The RM and Llama-based scores have high disagreement rates. Ultimately, select examples that are marked as high quality by the RM or the Llama-based filter.
- Difficulty scoring: For prioritizing examples that are more complex for the model, Meta score data using two measures of difficulty: intention tagging of SPT prompts, where more intentions implies more complexity and difficulty of dialogs on a three-point scale. Using a prompt Llama 3 70B
- Semantic deduplication: first cluster complete dialogs using RoBERTa and within each cluster sort them by quality score difficulty score.
- then do greedy selection by iterating through all sorted examples. and only keeping the ones that have maximum cosine similarity less than a threshold to the examples seen so far in the cluster.
Capabilities
1. Code
- Expert training : trained a code expert which is used to collect high quality human annotations for code
- Synthetic data generation : used 2.7M synthetic examples during SFT
- execution feedback :
- generate a large collection of programming problem descriptions
- generate solutions using Llama 3
- do a correctness analysis by running it thought a parser and a linter and doing unit test generation and execution
- error feedback and iterative self-correction, about 20% of solutions were initially incorrect but self-corrected
- fine-tuning and iterative improvement, with each round building on the previous one
- execution feedback :
- Programming language translation : due to lack of data on less common programming languages, Meta used a Llama 3 to translate code from a popular one.
- This improved performance significantly for less common languages
- System prompt steering during rejection sampling : During reject sampling process, Meta used code specific system prompts to improve code readability, documentation, thoroughness, and specificity.
- Filtering training data with execution and model-as-judge signals : use of “model-as-judge” in quality issues in rejection-sampled data.
2. Multilinguality
- Expert training : train a multilingual expert by branching off the pre-training run and continuing to pre-train on a data mix that consist of 90% multilingual tokens.
- Multilingual data collection : SFT data is collected from the expert trained above with overall distribution
- 2.4% human annotations,
- 44.2% data from NLP tasks,
- 18.8% rejection sampled data,
- 34.6% translated reasoning data.
3. Math and Reasoning
Reasoning
Meta defines reasoning as the ability to perform multi-step computations and arrive at the correct final answer.
- Challenges in training model that excel in mathematical reasoning
- Lack of prompts of higher complexity for SFT.
- Lack of ground truth chain of thought, which is essential for guiding the model how to break down the problem step-by-step and reach the final answer.
- Incorrect intermediate steps.
- Teaching models to use external tools.
- Discrepancy between training and inference. As at inference, there is feedback from user yield none such exist during training.
- To address these challenges,
- Figure out what model is not good at and source that data.
- Use Llama 3 to generate step-by-step solutions for a set of prompts.
- Train outcome & stepwise reward model to filter data with incorrect intermediate reasoning steps. For more challenging prompts, using Monte Carlo Tree Search (MCTS) with learned step-wise reward models to generate valid reasoning traces.
- Prompted Llama 3 to solve reasoning problems through a combination of textual and associated Python code.
- To learn from feedback and mistakes, Meta utilize incorrect generations, and perform error correction by prompting Llama 3 to yield correct generations.
4. Long Context
- During the final pre-training stage, context length of Llama 3 from 8k to 128k tokens.
- SFT and synthetic data generation: short-context data not good, give regressions in long-context capabilities. Relied on synthetic data.
- Observed that mixing 0.1% of synthetically generated long-context data with the original short-context data optimizes the performance across both short-context and long-context benchmarks.
5. Tool Use
- Trained to interact with
- Search Engine : Brave Search
- Python interpreter : to execute code
- Mathematical computational engine : can use Wolfram Alpha API
- Also got a good zero-shot tool use capabilities.
6. Factuality
- Meta follow the principle that post-training should align the model to ‘know what it knows’ rather than add knowledge.
- Knowledge probe
- Extract a data snippet from the pre-training data.
- Generate a factual question about these snippets by prompting Llama 3.
- Sample responses from Llama 3 to the question.
- Score the correctness of the generations using the original context as a reference and Llama 3 as a judge.
- Score the informativeness of the generations using Llama 3 as a judge
- Generate a refusal for responses which are consistently informative and incorrect across the generations, using Llama 3.
- This method makes sure model only answer what it knows. A good method to control hallucinations.
7. Steerability
- For generic foundational model, should be maximally steerable to different downstream use case easily.
- For that purpose
- Collect steerability preference samples
- Leverage this data for reward modeling, rejection sampling, SFT, and DPO to enhance Llama 3’s steerability.
Results